
Beautiful Soup Tutorial: Web Scraping mit Python
Das Internet stellt eine unvorstellbare Menge an Daten bereit, die sich für viele Tätigkeitsbereiche von der Forschung bis hin zur nächsten Startup-Idee eignen. Wenn wir diese Daten benutzen wollen müssen wir diese zunächst über eine Methode namens Web-Scraping aus dem Internet herunterladen. Python stellt über seine Vielfalt an Bibliotheken bereits viele Möglichkeiten zum Scraping von Webseiten bereit. In diesem Tutorial wird es hauptsächlich um die Bibliothek Beautiful Soup gehen.
Die Python Bibliotheken requests und Beautiful Soup sind mächtige Werkzeuge. Wenn du gerne einen praktischen Ansatz verfolgst und vielleicht schon ein paar Grundkenntnisse zu Python 3 (und ggf. HTML) mitbringst, ist dieses Tutorial genau richtig für dich.
Folgendes lernst du hier:
- Benutzung der
requestsBibliothek und Beautiful Soup zum Scrapen und Parsen von Webseiten-Daten - Den Prozess des Scraping von A-Z verstehen
- Du baust ein Python-Skript, um eine Liste von Blogbeiträgen von LerneProgrammieren.de herunterzuladen
Wenn du dieses Projekt durchgearbeitet hast, verfügst du über das nötige Wissen, jegliche Informationen von öffentlichen Webseiten auf der ganzen der Welt scrapen zu können.
Den gesamten Quellcode zu diesem Tutorial findest du wie immer in unserem kostenlosen Mitgliederbereich.
Los geht's!
Was ist Web Scraping?
Unter Web Scraping oder nur "Scraping" verstehen wir das Sammeln von Daten aus dem Internet, meist von Webseiten. Rein technisch gesehen ist das reine Markieren, Kopieren und Einfügen eines Wikipedia-Artikels bereits eine Form von Scraping.
Allerdings bezieht sich das Wort Web Scraping meist auf einen automatisierten Prozess. Du solltest im Vorhinein wissen, dass manche Webseiten-Betreiber es gar nicht mögen, wenn automatisierte Web-Scraper über ihre Seite laufen. Du solltest daher immer vorher den Webseiten-Betreiber fragen oder nach näheren Richtlinien, wie bspw. Nutzungsbedingungen, dazu auf der Seite suchen. Alle weiteren rechtlichen Aspekte zu Web-Scraping solltest du immer mit einem Experten klären.
Vorteile und Einsatzmöglichkeiten von Web Scraping
Angenommen, du bist ein großer Fan von unseren LerneProgrammieren-Tutorials. Du möchtest aber nicht immer manuell prüfen, ob ein neuer Blogbeiträg veröffentlicht wurde. Stattdessen entschließt du dich ein Python-Skript zu bauen, dass den LerneProgrammieren-Blog zu spezifischen Zeitpunkten (z.B. alle 12 Stunden) auf neue Beiträge überprüft. Wenn ein neuer Beitrag von deinem Python-Programm gefunden wurde, dann wird dieser Blogbeitrag automatisch per Web-Scraping ausgelesen (geparsed) und auf in deiner Cloud als Word-Datei abgelegt.
Mit ein bisschen Code-Anpassung lässt sich dieser automatisierte Prozess für fast jeden Blog umsetzen, den du täglich liest.
Oder wie wäre es mit einer Website für Stellenanzeigen, wenn du grade nach neuen Jobs als Programmierer suchst? Du kannst Python nutzen, langweilige Teile deiner Jobsuche zu automatisieren.
Die Web Scraping Automatisierung ist eine Lösung, um den Prozess der Datenerfassung zu beschleunigen. Du schreibst deinen Code einmal und er wird die Informationen, die du willst, immer wieder und von allen Seiten holen, die du im Code definiert hast.
Im Gegensatz dazu, wenn du versuchst, die gewünschten Informationen manuell zu bekommen, verbringst du möglicherweise viel Zeit mit Mausklicks, Scrollen und Suchen. Das gilt besonders, wenn du große Datenmengen von Webseiten benötigst, die regelmäßig mit neuen Inhalten aktualisiert werden. Manuelles Web Scraping kann eine Menge Zeit in Anspruch nehmen.
Es gibt so viele Informationen im Web und es kommen ständig neue Informationen hinzu. Irgendetwas unter all diesen Daten ist wahrscheinlich von Interesse für dich. Egal, ob du gerade auf Jobsuche bist, neue Blogbeiträge auf deinen Computer laden willst oder vielleicht per Messenger über die neuesten Aktienkurse informiert werden möchtest, kann dir Web Scraping bei diesen Anwendungsfällen helfen, schnell und effizient ans Ziel zu kommen.
Probleme beim Web Scraping
Jede Website benutzt eine andere Technologie sowie ein anderes Design. Das kann beim Web Scraping zu Problemen führen. Daher ist diese Vielfalt ein Problem, da jede Webseite eine andere Struktur und einen anderen Code hat. Jede Webseite braucht also ein anderes oder leicht abgeändertes Python-Programm, um Daten zu extrahieren.
Eine weitere Herausforderung ist die ständige Weiterentwicklung und Änderung der Websites. Der Scraper, den du heute baust, wird auf der gleichen Webseite in 6 Monaten nicht mehr funktionieren, wenn sich die Struktur oder der Code der Seite geändert hat. Die gute Nachricht ist, dass viele Änderungen an Websites eher geringfügig sind, sodass du deinen Scraper wahrscheinlich mit nur minimalen Anpassungen aktualisieren kannst.
Bedenke jedoch, dass sich das Internet ständig weiterentwickelt. Je mehr Scraper du erstellst, desto mehr Zeit musst du später in die Wartung stecken. Eine Möglichkeit, diese Änderungen zu überwachen liegt darin, eine Continous Integration einzurichten. Dadurch werden deine Scraper-Skripte regelmäßig getestet. Sobald Fehler auftreten, wirst du informiert, damit du diese prüfen und ggf. danach das Skript warten kannst.
Web Scraping oder API?
Einige Website-Anbieter bieten von Hause aus ihre Daten an, sei es kostenlos oder kostenpflichtig. Diese bereitgestellten Application Programming Interfaces (APIs) ermöglichen es dirihre Daten auf eine vordefinierte Weise abzurufen.
Mit APIs kannst du das Parsen von HTML vermeiden und stattdessen mit JSON- oder XML-Formaten direkt auf die Daten zugreifen. HTML ist in erster Linie ein Weg, um Inhalte visuell für die Nutzer darzustellen.
Wenn du eine API verwendest, ist der Prozess im Allgemeinen robuster im Vergleich zum Scraping. Das liegt daran, dass APIs extra zum Abrufen von Daten erstellt wurden. Der Vorteil einer API ist daher, dass diese immer noch funktioniert, auch wenn sich das Design oder die Struktur der Webseite stark ändern. Außerdem liegt die Wartung der API meist beim Webseiten-Anbieter und nicht bei dir! Das ist ein enormer Zeitvorteil.
Es sei jedoch angemerkt, dass sich natürlich auch API's weiterentwickeln und ändern können. Außerdem hast du keine Kontrolle über die Daten, die in der API bereitgestellt werden. Wenn eine API nicht die Informationen bereitstellt, die du extrahieren möchtest, bleibt dir nur die Möglichkeit beim API-Anbieter nett nachzufragen oder das Web-Scraping der fehlenden Daten.
Das waren die groben Unterschiede Web Scraping und APIs. In diesem Tutorial werden wir nur den Prozess des Web-Scraping abdecken, um den Rahmen nicht zu sprengen. Wenn dich APIs interessieren, findest du in unserem Blog weitere Ressourcen und Tutorials dazu.
Projekt: Blog-Daten Scrapen
In diesem Beautiful Soup Tutorial baust du einen Web Scraper, der eine Liste von Blogbeiträgen von LerneProgrammieren.de extrahiert. Dein Web Scraper wird den Quellcode abrufen und analysieren, um die Informationen herauszufiltern, die wir herunterladen wollen.
Im Prinzip kannst du jede Seite im Internet scrapen, die du dir anschauen kannst. Bei einigen Seiten ist es super leicht an die Informationen zu kommen, bei manchen Seiten ist es schwerer.
Dieses Tutorial bietet dir eine Einführung in das Web Scraping, damit du den gesamten Prozess nachvollziehen kannst. Danach kannst du den gleichen Prozess für jede Website anwenden, die du scrapen willst.
1. Webseite durchsuchen & inspizieren
Öffne die Seite, die du scrapen möchtest, mit deinem Standard-Browser (Chrome, Firefox, Safarfi, etc.)
Um die Informationen abzurufen, die du haben möchtest, musst du die Struktur der Webseite verstehen.
Werde zum Daten-Detektiv
Klicke dich durch die Seite. Benutze sie, so wie es ein normaler Besucher machen würde.

Auf dem obigen Screenshot sehen wir den Blog von LerneProgrammieren. Du siehst eine Auflistung einiger Blogbeiträge. In der rechten Sidebar sehen wir eine Suchleiste, sowie einige weitere Widgets. Wenn du auf einen der Beiträge klickst, ändert sich (selbstverständlich) der Inhalt sowie die die URL in der Adressleiste deines Browsers.
Parameter: Informationen in URLs verstehen
Eine Menge Informationen können in einer URL verschlüsselt werden. Das Web-Scraping wird viel einfacher, wenn du dich zuerst damit vertraut machst, wie URLs funktionieren und woraus sie bestehen.
Benutze z.B. das Suchfeld. Gib hier das Suchwort HTML ein.
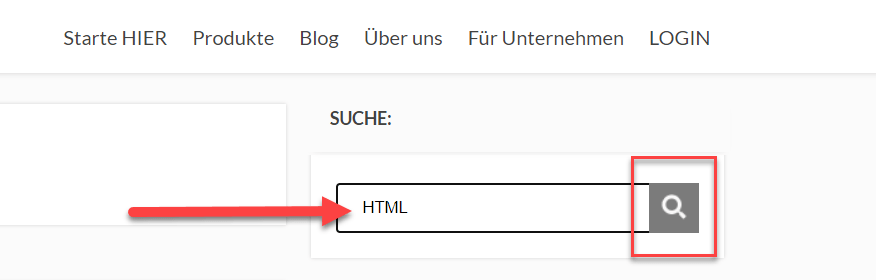
Die URL ändert sich nach der Suche wie folgt:
![]()
Du kannst die obige URL in zwei Hauptteile zerlegen:
- Basis-URL stellt die Domains bzw. den Pfad dar, auf dem du dich befindest. z.B. lerneprogrammieren.de/
- GET-Parameter stellen zusätzliche Werte dar, die auf fast jeder Webseite vorkommen. Im obigen Beispiel gibt es den Parameter
?s=HTML
Jede Unterseite, nach der du auf dieser Webseite suchst, hat die gleiche Basis-URL. Hingegen ändern sich die GET-Parameter je nachdem, wonach du suchst. Du kannst sie dir als Abfragezeichenfolgen vorstellen, die an die Datenbank gesendet werden, um bestimmte Datensätze abzurufen. In unserem Fall suchen wir nach "HTML" und bekommen dann auch nur Blogbeiträge angezeigt, die das Suchwort in der Überschrift oder im Text enthalten.
GET-Parameter verstehen
Die GET-Parameter bestehen in der Regel aus drei Komponenten:
- ?: Der Anfang der Abfrageparameter wird durch ein Fragezeichen (
?) gekennzeichnet. - Schlüssel-Wert-Paar: Die Informationen, die einen Abfrageparameter ausmachen, werden in Schlüssel-Wert-Paaren dargestellt. Verbunden werden die beiden durch ein Gleichheitszeichen.
- &-Trennzeichen (im obigen Beispiel nicht zu sehen): Jede URL kann mehrere Abfrageparameter haben, die durch ein kaufmännisches Und (
&)voneinander getrennt werden
Benutze das Suchfeld auf unserer Webseite erneut und gib dieses mal "JavaScript" ein. Du wirst sehen, dass du diesmal andere Beiträge angezeigt bekommst. Außerdem haben sich die Parameter in deiner Browser-Adressleiste erneut geändert.
Versuche einmal den Such-Parameter direkt in deiner Adressleiste zu ändern. Lösche dafür den Wert hinter ?s= und gib Python ein. Drücke dann auf Enter und warte bist die Seite neu geladen wird.
Du wirst feststellen, dass sich diese manuelle Parameterwert-Änderung in der Liste der angezeigten Blogbeiträge ausgewirkt hat. Wenn du URLs inspizierst, kannst du Informationen darüber erhalten, wie du Daten vom Server der Webseite abrufen kannst.
Untersuche die Webseite mit den Entwickler-Tools
Als nächstes möchtest du mehr darüber erfahren, wie die Daten über den Quellcode strukturiert sind. Du musst die Seitenstruktur in ihren Grundzügen verstehen, um aus dem HTML-Code das zu sammeln, was du extrahieren möchtest. Die Entwickler-Tools können dir helfen, die Struktur einer Webseite zu verstehen.
In allen modernen Browsern sind Entwickler-Tools installiert. In diesem Tutorial wirst du sehen, wie du mit den Entwicklertools in Chrome arbeitest. In anderen Browsern lassen sich diese Tools sehr ähnlich aufrufen.
In Chrome kannst du die Entwicklertools aufrufen, indem du einen Rechtsklick auf der Seite machst. Klicke dann auf "Untersuchen". Alternativ kannst du die Tastenkombination STRG + SHIFT + I drücken.
Mit den Entwicklertools erkunden wir das DOM (Document Object Model) einer Webseite. Dadurch können wir den Quelltext, mit dem wir arbeiten wollen besser zu verstehen.
Um in das DOM deiner Seite einzutauchen, wähle den Tab namens Elements in den Entwicklertools. Du wirst eine Struktur mit anklickbaren HTML-Elementen sehen. Du kannst Elemente direkt in deinem Browser erweitern, löschen und bearbeiten:

Jetzt bist du gefragt: Finde eine beliebige Beitragsüberschrift im DOM. In welches HTML-Element ist die Überschrift eingewickelt und welche anderen HTML-Elemente enthält sie?
Lass dir für diesen Schritt Zeit und spiele den Detektiv. Je mehr du die Seite kennenlernst, desto einfacher wird es sein, sie zu scrapen.
2. HTML-Inhalt von einer Seite scrapen
Jetzt wo wir uns die Seite angeschaut haben, ist es an der Zeit, unser Python-Programm zu schreiben.
Zuerst musst du den HTML-Code der Seite in dein Python-Skript übertragen, damit du mit ihm interagieren kannst. Für diese Aufgabe verwendest du die Requests-Bibliothek von Python. Falls du sie noch nicht installiert hast, kannst du folgendes in eine Kommandozeile deiner Wahl eingeben:
pip3 install requests
Öffne dann eine neue Datei in deinem bevorzugten Texteditor (z.B. Visual Studio Code, Notepad++).
Alles was du brauchst, um das HTML abzurufen, sind ein paar Zeilen Python-Code:
import requests
URL = 'https://lerneprogrammieren.de/?s=JavaScript'
website = requests.get(URL)
Was ist hier passiert? Dieser Code führt eine HTTP-Anfrage an die angegebene URL aus. Er ruf die HTML-Daten ab, die der Server zurückschickt und speichert diese Daten in einem Python-Objekt.
Wenn du einen Blick auf den heruntergeladenen Inhalt wirfst, dann wirst du feststellen, dass er dem HTML, das du zuvor mit den Entwickler-Tools inspiziert hast, sehr ähnlich sieht.
Ist jedoch ziemlich unübersichtlich in der Konsole, oder?
Um die Struktur der HTML-Anzeige in deinem Terminal zu verbessern, kannst du das .content-Attribut des Objekts mit pprint() ausgeben.
Statische Webseiten
Die Website, die du in diesem Tutorial scrapen willst, zeigt statischen HTML-Inhalt an. Hier sendet der Webserver ein HTML-Dokument zurück, das bereits alle Daten enthält, die du als Benutzer siehst.
Als du vorhin die Seite mit den Entwickler-Tools angeschaut hast, hast du entdeckt, dass ein Blogbeitrag der Liste aus dem folgenden HTML (unübersichtlich & lang) besteht:
<div class="awr">
<a href="https://lerneprogrammieren.de/uebersicht-ueber-die-programmiersprachen/#comments" class="cmt acm">54 <span class="trg"></span>
</a>
<div class="fwit"><a class="psb" href="https://lerneprogrammieren.de/uebersicht-ueber-die-programmiersprachen/">
<img src="https://lerneprogrammieren.de/wp-content/uploads/uebersicht-programmiersprachen.png"
alt="" title="Übersicht über die Programmiersprachen (2022)">
</a></div>
<h2 class="entry-title"><a href="https://lerneprogrammieren.de/uebersicht-ueber-die-programmiersprachen/">Übersicht
über die Programmiersprachen (2022)</a></h2>
<p>Dieser Artikel soll dir einen Überblick über die verschiedenen Programmiersprachen geben und soll dir zeigen,
dass die Programmiersprachen an sich gar nicht so verschieden sind. Hier werden die gängigsten
Programmiersprachen kurz vorgestellt und erklärt, diese wurden aus dem sogenannten TIOBE-Index genommen, welcher
die Beliebtheit von Programmiersprachen misst. Mit welcher Programmiersprache nun loslegen sollte, wird hier
[…]</p>
<a href='https://lerneprogrammieren.de/uebersicht-ueber-die-programmiersprachen/' class=''>Weiterlesen</a>
<div class="clear"></div>
</div>
Mit einem HTML-Formater kannst du den HTML-Code formatieren, um ihn leichter zu verstehen.
Hinweis: Behalte im Hinterkopf, dass jede Website eine andere HTML-Struktur besitzt. Deshalb ist es notwendig, die Struktur der Seite, mit der du gerade arbeitest, zu überprüfen und zu verstehen. Dann kannst du zum nächsten Schritt übergehen.
Der o.g. HTML-Code lässt sich wie folgt analysieren:
- Ein Blogbeitrag wird von einem <div>-Tag mit der CSS-Klassse "awr" umschlossen.
- Danach folgt ein Link auf den Beitrag, genauer sagt in den Kommentar-Bereich des Beitrags.
- Im Anschluss siehst du ein weiteres <div>-Tag, welches ein Bild, nämlich das Beitragsbild, umschließt.
- Als nächstes wird ein <h2>-Tag, nämlich die Überschrift des Blogbeitrags dargestellt. Das vorletzte Tag (<p>-Tag) ist ein kurzer Text-Auszug des Artikels.
- Zum Abschluss wird noch ein weiterer Link zum Artikel, mit dem Link-Text "Weiterlesen" angezeigt.
Solltest du dich jemals in einer unübersichtlichen HTML-Struktur verirren, denke daran, dass du jederzeit die Entwickler-Tools deines Browsers benutzen kannst, um dir Struktur interaktiv zu überprüfen.
Kurzer Zwischenstand:
Inzwischen hast du erfolgreich mit der der Python-Request-Bibliothek gearbeitet. Mit nur wenigen Zeilen Code war es möglich, HTML-Inhalte aus dem Web zu scrapen und diese für die weitere Verarbeitung verfügbar zu machen.
Es gibt jedoch ein paar komplexere Situationen, die beim Scrapen auftreten können. Bevor du daher mit Beautiful Soup startest, um relevante Informationen aus dem soeben heruntergeladenen HTML-Code herausfinden kannst, schaue dir diese zwei Sondersituationen an:
Sonderfall 1: Logins / Versteckte Webseiten
Viele Seiten verstecken sich hinter einem Login. Daher kommen wir ohne ein Benutzerkonto nicht an die Informationen, die wir scrapen wollen. Der Prozess, um eine HTTP-Anfrage von deinem Python-Skript aus zu starten, ist anders als sich auf der Webseite über einen Browser einzuloggen. Das bedeutet: Nur weil du dich per Python-Skript einloggen kannst, heißt das noch lange nicht, dass du auch an die zu beschaffenden Daten kommst.
Es gibt jedoch fortgeschrittene Techniken, die du über die Requests-Bibliothek benutzen kannst, um auf den Inhalt hinter Logins zuzugreifen. Diese Techniken erlauben es dir, dich auf Webseiten einzuloggen, während du die HTTP-Anfrage aus deinem Skript heraus machst.
Sonderfall 2: Dynamische Websites
Statische Websites sind einfacher zu bearbeiten, da der Server dir eine HTML-Seite als Antwort schickt. Diese Antwort enthält bereits alle Informationen. Du kannst die HTML-Antwort im Anschluss mit Beautiful Soup parsen und damit beginnen alle nötigen Daten herauszusuchen.
Hingegen kann es bei dynamischen Webseiten passieren, dass kein HTML vom Server zurückgesendet wird. Stattdessen erhältst du JavaScript als Antwort. Dein Browser wird den JavaScript-Code, den er von einem Server zurückerhält, gewissenhaft ausführen und das DOM und HTML lokal für dich erstellen. Wenn du jedoch in deinem Python-Programm eine Anfrage an eine dynamische Webseite stellst, bekommst du nicht den Inhalt der HTML-Seite.
Wenn du die requests-Bibliothek verwendest, erhältst du nur die Antwort des Servers. Im Falle einer dynamischen Website erhältst du JavaScript-Code, den du mit Beautiful Soup nicht parsen kannst. Der einzige Weg, um vom JavaScript-Code zu dem Inhalt zu gelangen, der dich interessiert, ist, den Code auszuführen, genau wie dein Browser es macht. Die Requests-Bib kann das nicht für dich tun, aber es gibt andere Lösungen, die das können.
Alternative Bibliotheken zum Arbeiten mit dynamischen Seiten:
Zum Beispiel ist requests-html ein Projekt, das dir dabei hilft JavaScript-Code zu rendern. Die Syntax für diese Bibliothek ist der "normalen" requests-Bibliothek ähnlich.
Eine weitere Alternative für das Scrapen und Parsen von dynamischen Webseiten ist das Selenium-Framework. Selenium emuliert einen echten Browser, der den JavaScript-Code für dich ausführt, bevor er die gerenderte HTML-Antwort an dein Skript weitergibt.
Wir werden in diesem Scraping-Tutorial nicht weiter auf diese Sondersituationen eingehen, um den Inhalt nicht zu sprengen. Derzeit sollte es ausreichen, dass du ein paar Alternativen (wie bspw. requests-html und Selenium) kennst, wenn du mit der requests-Bibliothek nicht weiterkommst.
3. HTML mit Beautiful Soup parsen
Du hast erfolgreich HTML-Code von einer Webseite gescraped. Doch irgendwie haben wir noch ein ziemliches Wirrwarr.
Der Code besitzt noch zu viele HTML-Tags und -Attribute. Daher wollen wir die Daten lesbarer machen und das heraussuchen, was uns interessiert.
Mit Beautiful Soup, einer weiteren Python-Bibliothek, kannst du strukturierte Daten parsen. Mit der Bibliothek kannst du also mit HTML auf eine ähnliche Art und Weise interagieren, wie du es zuvor mit den interaktiven Entwickler-Tools gemacht hast.
Beautiful Soup stellt eine Reihe von intuitiven Funktionen zur Verfügung, mit denen du das erhaltene HTML analysieren kannst. Bevor wir damit loslegen können, müssen wir Beautiful Soup zunächst über das Terminal herunterladen:
pip3 install beautifulsoup4
Wenn die Installation erfolgreich war, kannst du eine neue Python-Datei erstellen und dort die bs4-Bibliothek importieren:
import requests
from bs4 import BeautifulSoup
URL = 'https://lerneprogrammieren.de/blog/'
website = requests.get(URL)
results = BeautifulSoup(website.content, 'html.parser')
Was passiert in diesem einfachen Skript?
Die Variable "website" sendet eine HTTP-Anfrage an die URL und speichert den HTML-Inhalt ab.
Die letzte Zeile mit der Variable "results" erstellt ein in BeautifulSoup-Objekt, das den HTML-Inhalt, als Input entgegennimmt. Wenn das Objekt instanziiert wird, weist du Beautiful Soup zusätzlich an, den entsprechenden Parser zu verwenden. Im o.g. Beispiel ist das der HTML-Parser.
3.1 Elemente nach HTML-Klassennamen finden
Du hast bereits gelernt, dass jeder Blogbeitrag auf der /blog/ Unterseite ein <div>-Element mit der Klasse "awr" besitzt. Um alle Blogbeiträge zu parsen kannst du ein neues Beautiful Soup Objekt namens results erstellen. Zwischen diesem <div>-Element sind schließlich alle HTML-Teile, die uns interessieren.
So sieht das im Code aus:
blogbeitraege = results.find_all('div', class_='awr')
Hier rufst du die Methode .find_all() einem Beautiful Soup Objekt auf. Du bekommst dann alle das gesamte HTML für alle Blogbeiträge zurück, die auf der Seite angezeigt werden.
Mit einer for-Schleife kannst du alle Blogbeiträge auslesen:
for blogbeitrag in blogbeitraege:
print(blogbeitrag, end='\n'*2)
Der Code sieht schon besser aus, aber es ist immer noch viel HTML.
Nehmen wir an, du möchtest nur die Überschrift des Blogartikels extrahieren. Da das H2-Tag ebenfalls eine Klasse hat, können wir den Inhalt ganz einfach herauspicken.
Hier der Code:
for blogbeitrag in blogbeitraege:
blog_titel = blogbeitrag.find('h2', class_='entry-title')
print(blog_titel)
Output:

Super! Du kommst den Daten, an denen du eigentlich interessiert bist, immer näher. Wie du diese Ausgabe eingrenzen kannst, ohne die HTML-Elemente anzuzeigen, erfährst du im nächsten Abschnitt.
3.2 Text aus HTML-Elementen extrahieren
Im Moment willst du nur den Titel des Blogbeitrags herausfiltern, ohne weitere HTML-Tags. Beautiful Soup hat dafür bereits die Lösung für dich. Du kannst .text zu einem Beautiful Soup Objekt hinzufügen, um nur den Textinhalt der HTML-Elemente zurückzugeben:
for blogbeitrag in blogbeitraege:
blog_titel = blogbeitrag.find('h2', class_='entry-title')
print(blog_titel.text)
Output:

Führe das obige Code Snippet aus und du wirst den Textinhalt angezeigt bekommen. Allerdings wirst du auch eine Menge Whitespace (Leerzeichen) erhalten. Da du jetzt mit Python Strings arbeitest, kannst du die überflüssigen Leerzeichen mit .strip() entfernen. Du kannst auch alle anderen bekannten Python-String-Methoden anwenden, um deinen Text weiter zu bereinigen.
Hinweis: Das Web ist chaotisch und du kannst dich nicht darauf verlassen, dass die Struktur einer Seite konsistent ist. Daher wirst du beim Parsen von HTML öfters auf Fehler stoßen. Wenn du den obigen Code ausführst, könntest du folgenden AttributeError erhalten:
AttributeError: 'NoneType' object has not attribute 'text'
Wenn das der Fall ist, dann gehe einen Schritt zurück und untersuche deine vorherigen Ergebnisse. Gab es irgendwelche Elemente, die den Wert None ausgeben?
Es könnte sein, dass dort ein anderes Element enthalten ist, das leicht von den normalen Blogbeiträgen abweicht. Für dieses Tutorial kannst du das Element, das den Fehler auslöst einfach ignorieren. Nutze folgenden Code, um das Parsen des HTML-Elemente zu überspringen:
for blogbeitrag in blogbeitraege:
blog_titel = blogbeitrag.find('h2', class_='entry-title')
if None in (blog_titel):
continue
print(blog_titel.text)
Nachdem du den Code, wie oben gezeigt, geändert hast, führe dein Python-Skript erneut aus. Du solltest jetzt weitaus mehr Beitragsüberschriften angezeigt bekommen.
Output mit Fehlerbehandlung von "None"-Wert:

3.3 Elemente nach Klassenname und Textinhalt finden
Mittlerweile hast du die angezeigten Blogbeiträge relativ gut aufgeräumt. Obwohl das schon ziemlich ordentlich ist, kannst du dein Skript noch nützlicher machen. Auch wenn es sich hier um ein Python-Tutorial handelt, bist du zusätzlich an SQL-Datenbanken interessiert. Wäre es nicht hilfreich, wenn du die Blogbeiträge nach Schlüsselwörtern filtern könntest, die z.B. nur bestimmte Strings oder Schlüsselworte enthalten?
Strings mit exakter Übereinstimmung suchen:
Du weißt bereits, dass die Beitragsüberschriften auf der Website innerhalb von <h2>-Elementen angezeigt werden. Um nur nach bestimmten Inhalten zu filtern, kannst du das string-Argument verwenden:
sql_beitraege = results.find_all('h2', string='SQL')
Dieser Code findet alle <h2>-Elemente, bei denen der enthaltene String genau mit dem String "SQL" übereinstimmt. Beachte, dass du die Methode direkt auf deiner ersten Ergebnisvariablen aufrufst. Wenn du jetzt loslegst und die Ausgabe des obigen Codeschnipsels in deinem Terminal betrachtest, wirst du enttäuscht sein, weil kein Output zurückgegeben wird.
Es gab im obigen Output zwei Blogbeiträge die das Schlüsselwort "SQL" enthalten, also warum wird nichts angezeigt?
Wenn du string= verwendest, wie du es oben getan hast, sucht dein Python-Skript nach genau dieser Zeichenkette. Jegliche Unterschiede in der Großschreibung oder im Leerzeichen verhindern, dass das Element gefunden wird.
Im nächsten Abschnitt wirst du einen Weg finden, den String allgemeiner zu machen.
Strings über Regex suchen:
Wenn du nach Strings suchen möchtest, die ein Suchtwort enthalten, du aber nicht den exakten String kennst, kannst du Regex benutzen. Hinweis: Bevor du Regex benutzen kannst, musst du die "re"-Bibliothek importieren.
Schreibe den folgenden Code in den obersten Teil deines Python-Programms:
import re
Jetzt wo du die Regex-Bibliothek importiert hast, können wir damit arbeiten.
Deine for-Schleife musst du wie folgt abändern:
for blogbeitrag in blogbeitraege:
sql_beitraege = blogbeitrag(text=re.compile('SQL'))
print(sql_beitrage)
Output:

Dein Programm hat zwei Übereinstimmungen gefunden!
Hinweis: Falls du immer noch keinen Treffer erhältst, versuche deinen Suchstring anzupassen. Da sich unsere Blogbeiträge ständig ändern, kann es sein, dass du zu dem Zeitpunkt an dem du dieses Tutorial durcharbeitest, keinen Beitrag findest der das Keyword "SQL" in der Überschrift hat.
Damit du den Überblick behältst, ist hier der gesamte Code, um Suchbegriffe mit Regex zu finden:
import requests
from bs4 import BeautifulSoup
import re
URL = 'https://lerneprogrammieren.de/blog/'
website = requests.get(URL)
results = BeautifulSoup(website.content, 'html.parser')
blogbeitraege = results.findAll('h2', class_='entry-title')
for blogbeitrag in blogbeitraege:
sql_beitraege = blogbeitrag(text=re.compile('SQL'))
print(sql_beitrage)
3.4 Attribute aus HTML-Elementen extrahieren
An diesem Punkt hat dein Python-Skript bereits die Website gescraped und filtert deren HTML nach relevanten Überschriften, die dich interessieren.
Was jetzt noch fehlt ist, der Link eines Blogbeitrags, damit du dir diesen später z.B. im Browser anschauen kannst.
Während du die Seite inspiziert hast, hast du festgestellt, dass der Artikel-Link ebenfalls im H2-Tag der Überschrift umschlossen wird. Jedoch haben wir den Link in den vorigen Beispielen mit der .text() sowie der Regex-Funktion entfernt.
Um die eigentliche URL zu erhalten, musst du eines dieser Link-Attribute extrahieren, anstatt es zu verwerfen.
Schau dir die Liste der Blog-Beiträge erneut an, nachdem du folgenden Code ausgeführt hast:
import requests
from bs4 import BeautifulSoup
URL = 'https://lerneprogrammieren.de/blog/'
website = requests.get(URL)
results = BeautifulSoup(website.content, 'html.parser')
blogbeitraege = results.findAll('h2', class_='entry-title')
for blogbeitrag in blogbeitraege:
print(blogbeitrag)
Output:

Die URL ist im href-Attribut des verschachtelten <a>-Tags enthalten. Du solltest daher den Wert des href-Attributs extrahieren. Das machst du wie folgt:
for blogbeitrag in blogbeitraege:
link = blogbeitrag.find('a')['href']
print(link)
Die Ergebnisse zeigen nur Links zu Blogbeiträgen, die zwischen den H2-Blogüberschriften gefunden wurden.
3.5 Elemente nach ID finden
In einer HTML-Webseite kann jedem Element genau ein id-Attribut zugewiesen werden. Wie der Name schon sagt, macht dieses id-Attribut das Element auf der Seite eindeutig identifizierbar. Du kannst beginnen, deine Seite zu analysieren, indem du ein bestimmtes Element anhand seiner ID auswählst.
Wechsle zurück zu den Entwicklertools und suche ein HTML-Element auf unserer (oder einer beliebigen) Website, das eine ID enthält.
Hinweis: Denke daran, dass es hilfreich ist, regelmäßig in deinen Browser zurückzukehren, damit du die Seite interaktiv mithilfe der Entwicklertools untersuchen kannst.
Wenn du ein HTML-Element gefunden hast, das ein id="" Attribut enthält, kannst du in deinem Python-Code testen, ob du es auslesen kannst.
Mit Beautiful Soup kannst du ein spezifische Element wie folgt über seine ID zu finden:
id_suchen = result.find(id='IDNAME')
Wenn du die ID des Elements verwendest, kannst du ein Element aus dem Rest des HTMLs herauspicken. Das erlaubt es dir, nur mit diesem speziellen Teil des HTMLs der Seite zu arbeiten.
Zusätzliche Übungen zum Scrapen
Wenn du den Code parallel zu diesem Tutorial geschrieben hast, dann kannst du dein Skript bereits so ausführen, wie es ist. Um deine neuen Fähigkeiten auszubauen, kannst du den gesamten Web Scraping Prozess mit deinen Lieblingswebseiten wiederholen.
Hier ein paar "Scraping" Inspirationen:
- News-Webseiten
- Social Media Portale wie z.B. Reddit oder Twitter
- Job-Portale
Gehe das Tutorial noch einmal von vorne durch und verwende eine dieser Seiten. Du wirst sehen, dass die Struktur jeder Website anders ist und dass du den Code auf eine etwas andere Art und Weise nachbauen musst, um die gewünschten Daten zu erhalten.
Das ist gleichzeitig die beste Möglichkeit, um die Konzepte, die du gerade gelernt hast, zu üben. Auch wenn du an manchen Stellen hängen bleibst, gib nicht auf. Mit etwas Durchhaltevermögen, lässt sich jede Webseite scrapen.
Wenn du möchtest, kannst du dabei auch zusätzliche Funktionen von Beautiful Soup austesten. Nutze die offizielle Dokumentation als Leitfaden und Inspiration. Zusätzliche Übung wird dir helfen, das Web Scraping mit Python, requests und Beautiful Soup besser zu beherrschen.
Fazit zum Web Scraping Tutorial mit Beautiful Soup
Beautiful Soup steckt voller nützlicher Funktionen zum Parsen von HTML-Daten. Es ist ein zuverlässiger und hilfreicher Begleiter für das Web-Scraping. Du wirst nach dem Erstellen deiner ersten Scraper feststellen, dass Beautiful Soup die meisten deiner Parsing-Bedürfnisse abdeckt, von der Navigation bis hin zur erweiterten Suche durch die Ergebnisse.
In diesem Tutorial hast du gelernt, wie du in Python mit Bibliotheken wie Requests und Beautiful Soup Daten von Webseiten scrapen kannst. Du hast ein Python-Skript erstellt, das Blogbeiträge aus dem Internet zieht und hast den kompletten Web Scraping Prozess von Anfang bis Ende durchlaufen.
Mit diesen Informationen zu den Bibliotheken in deinem Toolkit kannst du nun weitermachen und schauen, welche anderen Webseiten du scrapen kannst! Viel Spaß dabei, aber bitte denk daran deine Fähigkeiten mit voller Verantwortung einzusetzen.
Falls du den gesamten Quellcode dieses Beautiful Soup Tutorials herunterladen möchtest, klicke bitte hier.
Wenn du weitere Tutorials zum Scraping oder zu Python sehen möchtest, schreibe einen Kommentar unter diesen Artikel.