
Wenn du eins der wichtigsten Werkzeuge für Datenanalyse kennenlernen möchtest, ist dieses Pandas Tutorial genau richtig für dich. Hier lernst du die wichtigsten Pandas-Funktionen kennen, um Daten zu analysieren, zu bereinigen, zu visualisieren, und aus den Daten zu lernen.
Was ist das Pandas-Modul?
Das Pandas-Modul ist ein vielseitiges Toolkit für Datenwissenschaftler und Analysten, die mit Python arbeiten. Während andere Bibliotheken, in Bezug auf Machine Learning oder Datenvisualisierung, eher im Rampenlicht stehen, handelt es sich bei Pandas um das Rückgrat vieler Datenprojekte.
Warum solltest du dich mit Pandas beschäftigen?
Du denkst über einen beruflichen Werdegang als Data-Scientist oder in einem Bereich der Wissenschaften nach?
Dann ist es sehr hilfreich, wenn nicht sogar notwendig, dass du einige Dinge über Pandas verstehst.
In diesem pandas-Tutorial lernst du die wichtigsten Informationen. Mitunter befassen wir uns mit der Installation sowie Verwendung von Pandas. Danach schauen wir uns die bekanntesten Datenanalyse-Module, matplotlib und scikit-learn, an und wie sie mit pandas zusammenarbeiten.
Wofür kann ich Pandas einsetzen?
Im Kern ist Pandas ein Werkzeug, um Daten zu analysieren, extrahieren und um Erkenntnisse aus diesen Daten zu gewinnen. Mithilfe von Pandas lernst du deine Daten kennen, indem du sie bereinigst, transformierst und dann analysierst.
Veranschaulichen wir den Einsatz an einem Beispiel aus der Praxis.
Du möchtest einen Datensatz erforschen, der in einer CSV-Datei auf deinem Computer gespeichert ist. Pandas extrahiert die Daten aus dieser CSV zunächst in einen DataFrame (eine Tabelle).
Danach hast du mitunter folgende Einsatzmöglichkeiten:
1. Statistiken berechnen und Fragen zu den Daten beantworten, wie bspw.:
-
- Was ist der Durchschnitt, Median, Minimal- oder Maximalwert jeder Spalte?
- Gibt es eine Korrelation zwischen Spalte A und Spalte B?
- Wie sieht die Verteilung der Daten in Spalte C aus?
2. Bereinige deine Daten, indem du z.B. fehlende Werte entfernst und Zeilen oder Spalten nach bestimmten Kriterien filterst
3. Visualisiere die Daten mithilfe von matplotlib und gebe sie als Balken-, Kreis- oder Liniendiagramm aus.
4. Speichere die bereinigten, transformierten Daten zurück in eine CSV-Datei, eine andere Datei oder direkt in eine Datenbank.
Bevor du dich jetzt in komplexe Visualisierungen stürzt, solltest du ein gutes Verständnis für die Grundlagen deines Datensatzes haben.
Und genau dafür eignet sich Pandas!
So beliebt ist Pandas übrigens (Stand Mai 2022):

Wie passt pandas in das Data Science Toolkit?
Das Pandas-Modul ist ein zentraler Bestandteil des Data-Science-Toolkits und wird auch in Verbindung mit anderen Modulen eingesetzt.
Pandas baut auf dem NumPy-Paket auf, was bedeutet, dass ein Großteil der Struktur von NumPy in Pandas verwendet oder repliziert wird. Daten in Pandas werden oft verwendet, um statistische Analysen in SciPy, Visualisierungs-Funktionen von Matplotlib und Machine Learning Algorithmen in Scikit-learn durchzuführen.
Tipp: Wenn du NumPy noch nicht kennst, findest du hier ein ausführliches NumPy Tutorial für Anfänger.
Während sich Jupyter Notebooks (kostenlos) als hervorragende Umgebung für die Verwendung von Pandas auszeichnet, kannst du auch jeden anderen Texteditor zur Erforschung und Modellierung deiner Daten benutzen.
Ein großer Vorteil von Jupyter Notebooks ist, dass wir Python-Code in einer Zeile ausführen können, anstatt den gesamten Quellcode einfügen zu müssen.
Das macht sich bei der Arbeit mit großen Datensätzen und komplexen Transformationen bemerkbar und spart viel Zeit. Jupyter Notebooks bieten darüber hinaus eine einfache Möglichkeit, die erstellten DataFrames und Plots von Pandas zu visualisieren.
Ab welchem Kenntnisstand kannst du mit Pandas starten?
Wenn du noch kein Vorwissen in der Programmierung mit Python hast, solltest du dir zunächst ein Grundlagenwissen aufbauen.
Während du keine Profi-Kenntnisse in der Softwareentwicklung mitbringen musst, solltest du wissen, was Variablen, Funktionen, Listen, Dictionaries und Schleifen sind.
Wenn du nach einem guten praxisorientierten Kurs für die Python-Grundlagen suchst, schaue dir den LerneProgrammieren Python-Schnellstartkurs an oder belege das ausführlichere Python-Bootcamp (Videokurs). Danach kannst du problemlos mit Pandas durchstarten.
Erste Schritte mit Pandas
Installieren und importieren
Die Pandas Installation ist einfach und schnell durchzuführen.
Öffne dein Terminal (für Mac-Nutzer) oder die Kommandozeile (für PC-Nutzer) und installiere es mit einem der folgenden Befehle:
conda install pandas
ODER
pip install pandas
Wenn du diesen Artikel gerade in einem Jupyter-Notebook liest, kannst du alternativ diesen Befehl ausführen:
!pip install pandas
Das! am Anfang führt die Zelle aus, als ob sie in einem Terminal wäre.Da wir die pandas-Bibliothek häufig nutzen, importieren wir sie mit einem kürzeren Namen (pd):
import pandas as pd
Nun zu den Grundkomponenten von pandas.
Kernkomponenten von pandas: Series und DataFrames
Die beiden Hauptkomponenten von pandas sind Series und DataFrame
Eine Series ist im Wesentlichen eine Spalte und ein DataFrameist eine mehrdimensionale Tabelle, die aus einer Sammlung von Series (Spalten) besteht.
Nachfolgende Abbildung soll das verdeutlichen:

DataFrames und Serien sind sich insofern ähnlich, als dass viele Operationen, die du mit dem einen machen kannst, auch mit der anderen gemacht werden können. Einige beispielhafte Anwendungen sind das Ausfüllen von Nullwerten und das Berechnen eines Mittelwertes.
Noch nicht alles verstanden? Kein Problem!
In den folgenden Abschnitten dieses Tutorials wirst du sehen, wie diese Komponenten funktionieren.
Ein DataFrame von Grund auf erstellen
Es ist sehr hilfreich zu wissen, wie DataFrames direkt in Python erstellt werden.
Das ist der Fall, wenn du neue Methoden und Funktionen testest, die du in der Pandas-Dokumentation entdeckst.
Es gibt mehrere Möglichkeiten, einen DataFrame von Grund auf zu erstellen, aber eine gute Option ist es, ein einfaches Dictionary zu verwenden.
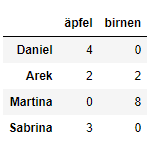
Praxisbeispiel - Unser Obststand (DataFrame):
Nehmen wir einmal an, dass wir einen Obststand haben. Dort werden Äpfel und Birnen angeboten. In unserem DataFrame wollen wir für jede Frucht eine eigene Spalte haben. Außerdem wollen wir eine neue Zeile für jede Kundenbestellung haben.
Um dies als Dictionary für Pandas zu realisieren, könnten wir es folgt schreiben:
data = { 'äpfel': [4, 2, 0, 3], 'birnen': [0, 2, 8, 0] }
Die Daten übergeben wir dann an den Pandas DataFrame-Konstruktor: Ergebnis/Ausgabe: Wie hat das funktioniert? Jedes (Schlüssel, Wert) Element in den Daten (data) entspricht einer Spalte im resultierenden DataFrame. Der Index dieses DataFrames wurde uns bei der Erstellung als die Zahlen 0-3 gegeben. Alternativ können wir unsere eigenen Indizes erstellen, wenn wir den DataFrame initialisieren. Hier ein Beispiel, in dem wir Kundennamen als Index nehmen: Ergebnis: Jetzt könnten wir also die Bestellung eines Kunden anhand seines Namens ausfindig machen: bestellungen.loc['Daniel'] Ergebnis: Später gehen wir weiter auf das Lokalisieren und Extrahieren von Daten aus dem DataFrame ein. Zunächst solltest du in der Lage sein, einen DataFrame mit beliebigen Daten zu erstellen, um damit zu lernen. Lass uns nun zu einigen schnellen Funktionen übergehen, um DataFrames aus externen Quellen (CSV, JSON, etc.) zu erstellen. Es ist recht einfach, Daten aus verschiedenen Dateiformaten in einen DataFrame zu laden. In den folgenden Beispielen werden wir weiterhin unsere Äpfel- und Birnen-Daten verwenden. Jedoch werden wir sie dieses Mal verschiedenen Dateien einlesen. Bei CSV-Dateien brauchst du nur eine einzige Zeile, um die Daten zu laden. Schau dir folgendes Beispiel an. Es ist super simpel: Ergebnis: CSVs haben keine Indizes wie unsere DataFrames, also müssen wir nur die Ergebnis: Hier setzen wir den Index auf die Spalte Null. Hinweis: Du wirst feststellen, dass die meisten CSV-Dateien keine Indexspalte haben. Daher musst du dir in den meisten Fällen keine Gedanken über diesen Schritt machen. Wenn du eine JSON-Datei hast, die im Wesentlichen ein gespeichertes Ergebnis: Beachte, dass unser Index dieses Mal korrekt dargestellt wird. Der Grund dafür ist, dass JSON die Verschachtelung von Indizes ermöglicht. Nachfolgend findest du die verwendete JSON-Datei als Referenz: bestellungen.json: Pandas wird versuchen herauszufinden, wie man einen DataFrame erstellt, indem es die Struktur deiner JSON-Datei analysiert. Ein Hinweis aus der Praxis: Manchmal klappt's und manchmal nicht! Manchmal musst du das Wenn du mit Daten aus einer SQL-Datenbank arbeitest, musst du zuerst eine Verbindung mit einer geeigneten Python-Bibliothek herstellen. Im Anschluss kann deine SQL-Abfrage an Pandas übergeben werden. Nachfolgend werden wir SQLite verwenden. Dafür benötigen wir das Modul Oder führe diesen Befehl aus, wenn du in einem Jupyter-Notebook bist: Output: So sollte es (ungefähr) aussehen, wenn pysqlite3 installiert wurde PySQLite3 wird verwendet, um eine Verbindung zu einer Datenbank herzustellen. Diese Datenbank benutzen wir dann, um einen DataFrame durch eine Hast du PySQLite3 installiert? Gut! Als Erstes werden wir eine Verbindung zu einer SQLite-Datenbankdatei herstellen: Hinweise zu anderen SQL-Datenbanken: Wenn du Daten in PostgreSQL, MySQL oder einem anderen SQL Server hast, musst du dir die richtige Python Bibliothek besorgen, um eine Verbindung herzustellen. Zum Beispiel ist In der folgenden SQLite Datenbank haben wir eine Tabelle namens bestellungen. Dabei befindet sich der Index in einer Spalte namens "index". Struktur: Unsere Daten: Indem wir eine SELECT-Abfrage und unsere Ergebnis: Genau wie bei CSV-Dateien ist es möglich, den Parameter Ergebnis: Tatsächlich können wir Das Indizieren von Serien (Series) und DataFrames ist eine häufige Aufgabe. Daher ist es gut, die verschiedenen Möglichkeiten zu kennen, um das zu erreichen. Nachdem du dich also ausgiebig mit der Bereinigung deiner Daten beschäftigt hast, bist du nun bereit, sie als Datei deiner Wahl zu speichern. Ähnlich wie beim Einlesen der Daten bietet Pandas intuitive Befehle, um sie zu speichern: Wenn wir JSON- und CSV-Dateien speichern, müssen wir in diese Funktionen nur unseren gewünschten Dateinamen mit der entsprechenden Dateierweiterung eingeben. Mit SQL erstellen wir keine neue Datei, sondern fügen eine neue Tabelle in die Datenbank ein, indem wir unsere bestehende Variable db_verbindung nutzen. Ausgezeichnet! Im nächsten Abschnitt wollen wir Daten aus der echten Welt importieren und damit ein paar Operationen durchführen, die häufig benötigt werden. DataFrames verfügen über unzählige Funktionen und Operationen, die für viele Datenanalysen wichtig sind. Als Anfänger musst du nicht alle Operationen auswendig lernen oder kennen. Es reicht, wenn du einfache Transformationen deiner Daten durchführen kannst, um grundlegende statistische Auswertungen widerzuspiegeln. Wir laden diesen Datensatz mit beliebten Filmen aus einer CSV-Datei und bestimmen den Filmtitel ("titel") als Index. Hinweis: Fällt dir in der obigen Code-Zeile noch etwas auf? Wenn du mit Excel arbeitest und eine CSV-Datei speicherst, wird standardmäßig das Semikolon, anstatt das Komma als Trennzeichen (Delimiter) benutzt. In der obigen Zeile definieren wir mit dem Ergebnis: Das Erste, was du machen solltest, wenn du einen neuen Datensatz öffnest ist, ein paar Zeilen anzuzeigen, um sie als visuelle Referenz zu behalten. Das erreichen wir mit Ergebnis: Obiger Befehl würde bspw. die ersten zehn Zeilen ausgeben. Einfach, oder? Um die letzten fünf Zeilen zu sehen, benutze Das Schlüsselwort Im folgenden Fall geben wir die letzten zwei Zeilen aus: Ergebnis: Wenn wir einen Datensatz laden, schauen wir uns zunächst die ersten fünf Zeilen an, um einen Überblick zu unseren Daten zu bekommen. Hier sehen wir die Namen der einzelnen Spalten, den Index und Beispiele von Werten in jeder Zeile. Du wirst bemerken, dass der Index in unserem DataFrame die Spalte titel ist. Das erkennst du im obigen Screenshot daran, dass das Wort Titel etwas niedriger steht als der Rest der Spalten. Ergebnis: Den Datentyp (Dtype) zu sehen, ist ziemlich nützlich. Stell dir vor, du hast gerade eine JSON-Datei importiert und die Ganzzahlen wurden als Strings aufgezeichnet. Du willst ein wenig rechnen und findest eine "unsupported operand" Exception, weil du nicht mit Strings rechnen kannst. Wenn du Ein weiteres schnelles und nützliches Attribut ist Ergebnis: Beachte, dass Wir haben also 250 Zeilen und 5 Spalten in unserem Filme-DataFrame. Du wirst Unser Film-Datensatz hat keine doppelten Zeilen. Dennoch ist es immer wichtig zu überprüfen, dass du keine Duplikate aggregierst: Ergebnis: Die Verwendung von Wir speichern die Daten der Kopie in der Variablen Im obigen Beispiel sollte dir, durch das Aufrufen von Jetzt können wir versuchen, die soeben erstellten Duplikate wieder zu löschen: Ergebnis: Genau wie Jedoch dieses Mal mit entfernten Duplikaten. Der Aufruf von Es ist ein einfach, DataFrames immer wieder der gleichen Variable zuzuweisen, wie in diesem Beispiel. Deswegen gibt es in Pandas das Nun wird unser Ein weiteres wichtiges Argument für 1. First Da wir im vorherigen Beispiel das Das bedeutet, dass Pandas, wenn zwei Zeilen gleich sind, die zweite Zeile verwirft und die erste Zeile behält. 2. Last Die Verwendung von 3. False Ergebnis: Was ist passiert? Da alle Zeilen Duplikate waren, hat das Argument Wenn du dich fragst, warum du das tun solltest: Ein dafür Grund ist, dass du so alle Duplikate in deinem Datensatz finden kannst. Bei den bedingten Auswahlen unten siehst du, wie du das machst. Oftmals haben Datensätze ausführliche Spaltennamen mit Groß- und Kleinschreibung, Leerzeichen, Symbolen sowie Tippfehlern. Um die Auswahl der Daten nach Spaltennamen zu vereinfachen, können wir ein wenig Zeit damit verbringen, die Namen zu bereinigen. Hier siehst du, wie du die Spaltennamen des Datasets anzeigst: Ergebnis: Die Methode Wir können die Methode Wir wollen bspw. die Spalte "jahr" in "Erscheinungsjahr" umbenennen. Das Ganze geht so: Ergebnis: Sehr gut! Aber was ist, wenn wir alle Spaltennamen kleinschreiben wollen? Anstatt jede Spalte manuell umzubenennen, können wir Ergebnis: Es ist immer eine gute Idee, Kleinbuchstaben zu verwenden, Sonderzeichen zu entfernen und Leerzeichen durch Unterstriche zu ersetzen, wenn du für einige Zeit mit einem Datensatz arbeitest. Wenn du Daten untersuchst, wirst du höchstwahrscheinlich auf fehlende Werte oder Null-Werte stoßen (die im Wesentlichen Platzhalter für nicht existierende Werte sind). Am häufigsten wirst du Pythons Es gibt zwei Möglichkeiten, mit Nullwerten zu arbeiten: Lass uns zunächst die Gesamtzahl der Nullen in jeder Spalte unseres Datensatzes berechnen. Der erste Schritt ist zu prüfen, welche Zellen in unserem DataFrame null enthalten: Ergebnis: Beachte, dass Um die Anzahl der Nullen in jeder Spalte zu zählen, verwenden wir eine Summenfunktion, zum Addieren der Daten: Ergebnis: Die Funktion Wir können nun sehen, dass unsere Daten 5 fehlende Werte enthalten. Data Scientists und Analysten stehen regelmäßig vor dem Dilemma, fehlende Werte zu entfernen oder zu imputieren. Insgesamt wird das Entfernen von Nullwerten nur dann empfohlen, wenn eine geringe Datenmenge fehlt. Nullwerte zu entfernen ist ziemlich einfach, wie das folgende Beispiel zeigt: Diese Operation löscht jede Zeile mit mindestens einem Nullwert, aber sie gibt einen neuen DataFrame zurück, ohne den ursprünglichen zu verändern. Du kannst auch Im Fall unseres Datensatzes würde diese Operation 5 Zeilen entfernen. Wird die obige Funktion .dropna() ausgeführt, würden die kompletten Zeilen der 5 fehlenden "bewertungAnzahl"-Zellen gelöscht. Das Löschen der gesamten Zeilen scheint suboptimal zu sein, da die anderen Spalten schließlich gute Daten enthalten. Um das Problem besser zu lösen, schauen wir uns als Nächstes die Imputation an. Du kannst nicht nur Zeilen löschen, sondern auch Spalten mit Nullwerten, indem du das Argument In unserem Datensatz würde diese Operation die Spalte "bewertungAnzahl" verwerfen. Hinweis: Was hat es mit diesem Ergebnis: Wie wir oben gelernt haben, ist dies ein Tupel, das die Form des DataFrame repräsentiert, sprich 250 Zeilen und 5 Spalten. Beachte, dass die Zeilen des Tupels bei Index Null sind und die Spalten des Tupels bei Index Eins. Das ist der Grund, warum Imputation ist eine Technik, die verwendet wird, um wertvolle Daten zu behalten, die Nullwerte enthalten. Es kann vorkommen, dass das Löschen der Zeilen mit einem Nullwert einen zu großen Teil deines Datensatzes entfernt. Stattdessen können wir diesen Nullwert mit einem anderen Wert imputieren, was man normalerweise dem Mittelwert oder dem Median dieser Spalte macht. Schauen wir uns nun die fehlenden Werte in der Spalte Gut zu wissen: Mit den eckigen Klammern wählen wir Spalten in einem DataFrame aus. Wenn du dich an den Abschnitt zum Erstellen von DataFrames erinnerst, weißt du, dass dort die Schlüssel des Die Bewertungen enthalten nun eine Serie: Ergebnis: Eine etwas andere Formatierung als ein DataFrame, aber wir haben immer noch unseren Wir imputieren die fehlenden Werte der Bewertungsanzahl mithilfe des Mittelwertes. Hier ist die Pandas-Funktion für den Mittelwert: Ergebnis: Mit dem Mittelwert füllen wir nun die Nullen mit Wir haben nun alle Nullen in Überprüfen wir nun erneut die Nullwerte im Filme-DataFrame: Ergebnis: Eine ganze Spalte mit dem gleichen Wert zu imputieren, ist ein einfaches Beispiel. Es wäre eine bessere Idee, eine granulare Imputation nach Genre oder Direktor zu versuchen. Du könntest z.B. den Mittelwert der Einnahmen in jedem Genre einzeln ermitteln und die Nullen in jedem Genre mit dem Mittelwert des Genres berechnen. Schauen wir uns nun weitere Möglichkeiten an, den Datensatz zu untersuchen und zu verstehen. Mit Ergebnis: Zu verstehen, welche Zahlen kontinuierlich sind, ist auch nützlich, wenn du über die Art der Darstellung nachdenkst, die du verwenden willst, um deine Daten visuell darzustellen. Ergebnis: Da die Spalte 'jahr' Integer-Werte enthält, wird durch das Ausführen des obigen Befehls, eine Berechnung folgender Kennzahlen wie bspw. Anzahl, Mittelwert, Standardabweichung, Min- sowie Max-Wert und die Verteilung (25%, 50%, 75%), durchgeführt. Ergebnis: Mithilfe der Korrelations-Funktion Ergebnis: Korrelationstabellen sind eine numerische Darstellung der bivariaten Beziehungen im Datensatz. Was bedeutet das? Positive Zahlen zeigen eine positive Korrelation an - eine steigt, die andere sinkt - und negative Zahlen stehen für eine umgekehrte Korrelation - eine steigt, die andere sinkt. Hinweis: 1.0 zeigt eine perfekte Korrelation an. Wenn wir uns im obigen Beispiel die erste Zeile und die erste Spalte anschauen, sehen wir, dass der Die Untersuchung von bivariaten Beziehungen ist hilfreich, wenn du ein Ergebnis oder eine abhängige Variable im Auge hast und sehen möchtest, welche Merkmale am stärksten mit der Zunahme oder Abnahme des Ergebnisses korrelieren. Du kannst bivariate Beziehungen visuell mit Scatterplots darstellen (zum Plotting bzw. einfache Datenvisualisierung kommen wir im nächsten Abschnitt). Schauen wir im Folgenden die Manipulation von DataFrames an. Bis jetzt haben wir uns auf einige grundlegende Zusammenfassungen unserer Daten konzentriert. Wir haben bereits das einfache Extrahieren von Spalten mithilfe von eckigen Klammern kennengelernt. Außerdem haben wir Nullwerte in einer Spalte mit Im Folgenden findest du weitere Manipulationen, wie bspw. Funktionen für das Slicen, Selektieren und Extrahieren von Daten. Diese Funktionen wirst du ständig benutzen. Es ist wichtig zu beachten, dass, obwohl viele Methoden gleich sind, DataFrames und Serien (Series) unterschiedliche Attribute haben. Daher musst du immer wissen, mit welchem Typ du arbeitest, da du sonst Attributfehler bekommst. Lass uns zuerst die Arbeit mit Spalten betrachten. Du hast bereits gesehen, wie man eine Spalte mit eckigen Klammern wie folgt extrahiert: Ergebnis: Obiger Code-Zeilen werden eine Series zurückgeben. Um eine Spalte als DataFrame zu extrahieren, musst du eine Liste von Spaltennamen übergeben. In unserem Fall ist das nur eine einzelne Spalte: Ergebnis: Da es nur eine Liste ist, ist das Hinzufügen eines weiteren Spaltennamens einfach: Ergebnis: Jetzt schauen wir uns an, wie wir Daten aus Zeilen bekommen. Für Zeilen haben wir zwei Optionen: Denke daran, dass wir immer noch nach dem Filmtitel indiziert sind, also geben wir Ergebnis: Allerdings geben wir mit Ergebnis: Um dies noch weiter zu verdeutlichen, lass uns einmal mehrere Zeilen auswählen. Wie würdest du das mit einer Liste machen? In Python kannst du Listen mit eckigen Klammern slicen, bspw. so: In Pandas funktioniert das Slicing auf die gleiche Weise: Ergebnis: Ein wichtiger Unterschied zwischen der Verwendung von Wenn wir Das Slicen mit Wir haben uns angeschaut, wie man Spalten und Zeilen auswählt. Doch was ist, wenn wir eine Auswahl mit einer Bedingung treffen wollen? Was ist zum Beispiel, wenn wir unser Filme-DataFrame so filtern wollen, dass er nur Filme anzeigt, bei denen das Jahr 2008 ist oder Filme mit einer Bewertung größer oder gleich 7,5? Um das zu lösen, nehmen wir eine Spalte aus dem DataFrame und wenden eine Boolean-Bedingung auf sie an. Hier ist ein Beispiel für eine solche Bedingung: Ergebnis: Ähnlich wie Wir möchten alle Filme herausfiltern, bei denen das Jahr nicht 2008 ist. Mit anderen Worten, wir wollen die False-Filme nicht anzeigen. Um die Zeilen zurückzugeben, in denen die Bedingung True ist, müssen wir diese Operation im DataFrame übergeben: Ergebnis: Du kannst dich daran gewöhnen, diese Bedingung zu betrachten, indem du sie wie folgt liest: (Das wird dir bekannt vorkommen, wenn du dich mit SQL auskennst) Wähle Daten aus Schauen wir uns die bedingte Auswahl mit weiteren Operatoren an, indem wir unser DataFrame nach Bewertungen filtern: Ergebnis: Doch wir können auch komplexere Bedingungen erstellen, indem wir Logikoperatoren benutzen. Lass uns den DataFrame so filtern, dass nur Filme aus dem Jahr 1997 UND eine Bewertung größer als 8.1 angezeigt werden: Ergebnis: Wir müssen sicherstellen, dass wir die Auswertungen mit Klammern gruppieren, damit Python weiß, wie es die Bedingung auswerten soll. Mit der Ergebnis: Es ist möglich, über einen DataFrame oder eine Serie zu iterieren, wie du es mit einer Liste machen würdest. Jedoch ist das bei besonders großen Datensätzen sehr langsam. Eine effiziente Alternative ist die Anwendung einer Funktion auf den Datensatz. Wir könnten etwa eine Funktion verwenden, um Filme mit einer Bewertung von 8.0 oder höher in einen String-Wert von "gut" und den Rest in "schlecht" zu konvertieren. Diese transformierten Werte können wir dann verwenden, um eine neue Spalte zu erstellen. Dafür würfen wir zunächst eine Funktion erstellen, die bei einer Bewertung (im Folgenden als "bew" abgekürzt) feststellt, ob sie gut oder schlecht ist: Jetzt wollen wir die gesamte Bewertungsspalte durch diese Funktion schicken. Dafür benutzen wir Ergebnis: Die Methode Diese Serie wird dann einer neuen Spalte namens Du kannst auch anonyme Funktionen verwenden. Diese Lambda-Funktion erreicht das gleiche Ergebnis wie Ergebnis: Insgesamt wird die Verwendung von Vektorisierung ist ein Stil der Computerprogrammierung, bei dem Operationen auf ganze Arrays statt auf einzelne Elemente angewendet werden. Ein gutes Beispiel, bei dem die Eine riesen Vorteil von Pandas ist, dass es sich in Matplotlib integrieren lässt. Damit hast du die Möglichkeit, deine DataFrames und Serien zu visualisieren (plotten). Um damit zu starten, müssen wir das Modul für Matplotlib importieren. Falls du das Modul noch nicht installiert hast, öffne dein Terminal und gib folgenden Befehl ein, um die Installation zu starten: Import von matplotlib in Python: Alles nachgebaut? Dann geht es weiter. Es wird nicht viel über das Plotten berichtet, aber es sollte reichen, um deine Daten leichter zu erforschen. Lass uns die Beziehung zwischen dem Veröffentlichungsjahr ('jahr') und der Bewertung visualisieren. Alles, was wir tun müssen, ist die Funktion Beispiel eines Scatter-Plots: Ergebnis: Was hat es mit dem Semikolon auf sich? Das ist kein Syntaxfehler, sondern nur eine Möglichkeit, die nervige Meldung (<AxesSubplot:title={'center':'Jahr vs. Bewertung'}, xlabel='jahr', ylabel='bewertung'>) zu verstecken, wenn du bspw. in Jupyter Notebooks plottest. Wenn wir ein einfaches Histogramm, basierend auf einer einzelnen Spalte plotten wollen, können wir es wie folgt aufrufen: Ergebnis: Erinnerst du dich an die Methode Nun, es gibt eine grafische Darstellung des Inter-Quartil-Bereichs, genannt Boxplot. Erinnern wir uns daran, was uns Ergebnis: Mit einem Box-Plot können wir diese Daten visualisieren: Ergebnis: Kurze Erklärung zum Boxplot: Das Erforschen, Bereinigen, Transformieren und Visualisieren von Daten mit Pandas in Python ist eine wesentliche Fähigkeit in der Datenwissenschaft. Allein das Bereinigen von Daten macht ca. 80% deines Jobs als Data-Scientist aus. Auch wenn dieses Pandas Tutorial bereits viele Funktionen abgedeckt hat, würden weitere Beispiele nur den Rahmen sprengen. Um dich weiter zu verbessern, empfehle ich dir daher, dir weitere umfangreiche Tutorials in den offiziellen Pandas-Dokus anzusehen, ein paar LerneProgrammieren-Onlinekurse zu Python und Datenwissenschaften zu absolvieren sowie insbesondere deine eigenen Projekte durchzuführen.
bestellungen = pd.DataFrame(data)
bestellungen # Erstelle eine Ausgabe

bestellungen = pd.DataFrame(data, index=['Daniel', 'Arek', 'Martina', 'Sabrina'])
bestellungen
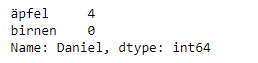
Externe Daten in Pandas laden
Daten aus CSV-Dateien einlesen
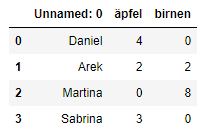
df = pd.read_csv('bestellungen.csv')
df
index_colbeim Lesen angeben:
df = pd.read_csv('bestellungen.csv', index_col=0)
df

Daten aus JSON-Formaten lesen
Python-Dictionaryist, kann Pandas diese genauso einfach einlesen:
df = pd.read_json('bestellungen.json')
df

[
{
"": "Daniel",
"äpfel": 4,
"birnen": 0
},
{
"": "Arek",
"äpfel": 2,
"birnen": 2
},
{
"": "Martina",
"äpfel": 0,
"birnen": 8
},
{
"": "Sabrina",
"äpfel": 3,
"birnen": 0
}
]
orient Schlüsselwort setzen. Schau dir dazu die read_json Dokumentation an.Daten aus einer SQL-Datenbank lesen
pysqlite3. Wenn du es noch nicht installiert hast, führe folgenden Befehl in deinem Terminal aus:
pip install pysqlite3
!pip install pysqlite3
Wofür brauchen wir PySQLite3?
SELECT-Abfrage zu generieren.
import sqlite3
db_verbindung = sqlite3.connect("bestellungen.db")
psycopg2 eine häufig verwendete Bibliothek, um Verbindungen zu PostgreSQL herzustellen. Außerdem würdest du eine Verbindung zu einer Datenbank-URI herstellen, anstatt zu einer Datei, wie wir es hier mit SQLite gemacht haben.Als Referenz - So sieht die Datenbankdatei (bestellungen.db) aus:
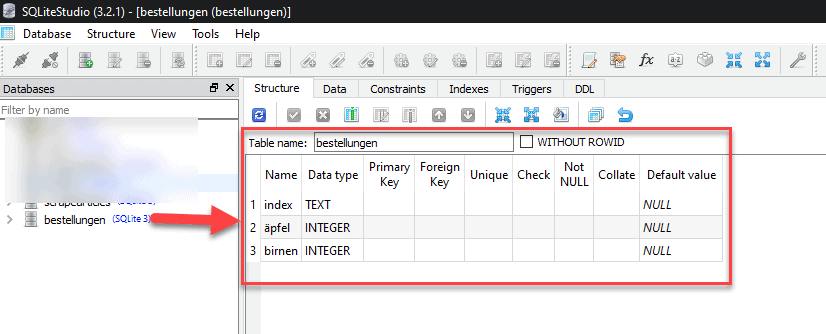
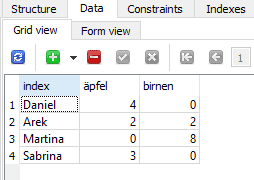
db_verbindung übergeben, können wir aus der Tabelle Bestellungen lesen:
df = pd.read_sql_query("SELECT * FROM bestellungen", db_verbindung)
df
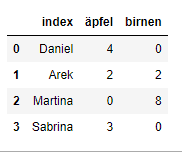
index_col='index'zu übergeben. Jedoch ist es auch möglich, den Index nachträglich zu definieren.
df = df.set_index('index')
df
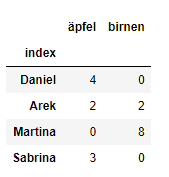
set_index()
Daten zurück konvertieren (CSV, JSON oder SQL)
df.to_csv('bestellungen_neu.csv')
df.to_json('bestellungen_neu.json')
df.to_sql('bestellungen_neu', db_verbindung)
Die wichtigsten DataFrame Operationen im Pandas Tutorial
df_filme = pd.read_csv("filme.csv", index_col="titel", sep=';')
sep Argument, dass Python das Semikolon ; als Trennzeichen beim Datenimport verwenden soll.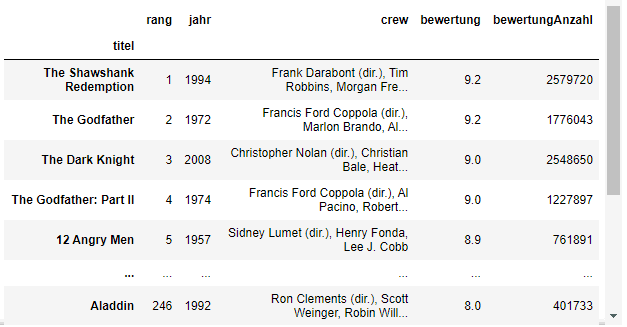
Neuen Datensatz anschauen
.head()
.head(). Probier es selbst aus:
df_filme.head()

.head() gibt standardmäßig die ersten fünf Zeilen deines DataFrame aus. Außerdem ist es möglich, eine Zahl zu übergeben:
df_filme.head(10)
.tail()
.tail().tail()akzeptiert ebenfalls eine Zahl als Argument.
df_filme.tail(2)

Informationen über deine Daten erhalten
.info()
.info()sollte einer der ersten Befehle sein, die du nach dem Laden deiner Daten ausführst:
df_filme.info()
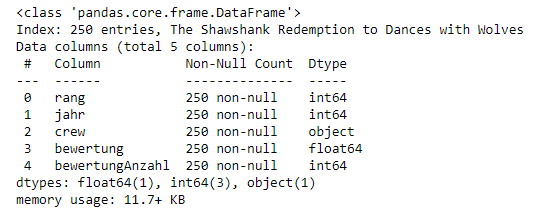
.info() liefert die wesentlichen Details über deinen Datensatz, wie z.B.:
.info() aufrufst, wird dir schnell klar, dass deine vermeintliche "Integer" Spalte, in Wirklichkeit String-Objekte sind..shape
.shape. Shape gibt ein Tupel aus (Zeilen, Spalten):
df_filme.shape
(250, 5)
.shape keine Klammern hat und ein einfaches Tupel des Formats (Zeilen, Spalten) beinhaltet..shape oft verwenden, wenn du Daten bereinigst und transformierst. Du könntest etwa einige Zeilen nach bestimmten Kriterien filtern und möchtest dann schnell wissen, wie viele Zeilen entfernt wurden.Arbeiten mit Duplikaten
.append()
df_temp = df_filme.append(df_filme)
df_temp.shape
(500, 5)
append() wird eine Datenkopie zurückgeben, ohne den ursprünglichen DataFrame zu verändern.df_temp, sodass wir nicht mit den echten Daten arbeiten..shape, auffallen, dass sich unsere DataFrame-Zeilen verdoppelt haben (von 250 Zeilen auf 500 Zeilen)..drop_duplicates()
df_temp = df_temp.drop_duplicates()
df_temp.shape
(250, 5)
append(), gibt auch die drop_duplicates() -Funktion eine Kopie deines DataFrame zurück..shape bestätigt, dass wir wieder bei den 250 Zeilen unseres ursprünglichen Filme-Datensatzes angekommen sind.inplace Argument. Wenn du inplace=Trueverwendest, wird das DataFrame Objekt an Ort und Stelle modifiziert:
df_temp.drop_duplicates(inplace=True)
df_temp automatisch die transformierten Daten enthalten.drop_duplicates() ist keep, dass drei mögliche Optionen kennt:
first: (Standard) Duplikate bis auf das erste Vorkommen verwerfen.last: Duplikate bis auf das letzte Vorkommen verwerfen.False: Alle Duplikate verwerfen.keep Argument nicht definiert haben, wurde es (standardmäßig) auf first gesetzt.last hat den gegenteiligen Effekt: Die erste Zeile wird verworfen.False hingegen verwirft alle Duplikate. Wenn zwei Zeilen gleich sind, werden beide verworfen. Beobachte, was mit df_temppassiert:
df_temp = df_filme.append(df_filme) # Erstelle neue Kopie
df_temp.drop_duplicates(inplace=True, keep=False)
df_temp.shape
(0, 5)
keep=False sie alle verworfen. Das hat dazu geführt, dass null Zeilen übrig blieben.Spalten bereinigen
.columns
df_filme.columns
Index(['rang', 'jahr', 'crew', 'bewertung', 'bewertungAnzahl'], dtype='object')
.columns ist praktisch, wenn du Spalten umbenennen willst, indem du sie einfach kopieren und einfügen kannst. Weiterhin ist es hilfreich, wenn du verstehen musst, warum du einen Key Error erhältst, wenn du Daten nach Spalten auswählst..rename()
.rename() verwenden, um bestimmte oder alle Spalten eines Python-Dictionaryumzubenennen.
df_filme.rename(columns={ 'jahr': 'Erscheinungsjahr' }, inplace=True)
df_filme.columns
Index(['rang', 'Erscheinungsjahr', 'crew', 'bewertung', 'bewertungAnzahl'], dtype='object')
.lower() verwenden:
df_filme.columns = [col.lower() for col in df_filme]
df_filme.columns
Index(['rang', 'erscheinungsjahr', 'crew', 'bewertung', 'bewertunganzahl'], dtype='object')
list (und dict) Comprehensions sind sehr nützlich, wenn man mit Pandas und Daten im Allgemeinen arbeitet.Wie man mit fehlenden Werten in Pandas arbeitet
None oder NumPys np.nan sehen. In gewissen Situationen werden diese unterschiedlich behandelt.
df_filme.isnull()
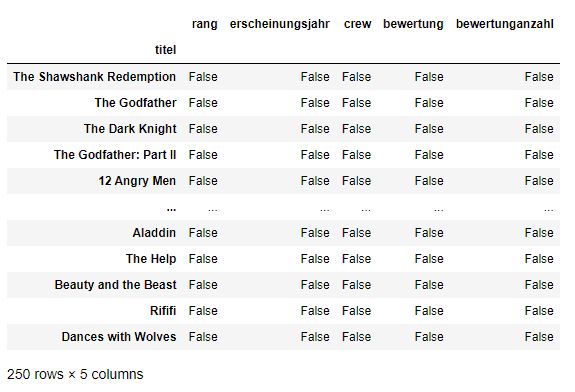
isnull()einen DataFrame zurückgibt, in dem jede Zelle entweder True oder False ist, abhängig vom Null-Status der Zelle.
df_filme.isnull().sum()
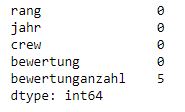
.isnull() allein ist nicht sehr nützlich. Daher wird sie meist in Verbindung mit anderen Methoden, wie sum(), verwendet.Entfernen von Nullwerten
df_filme.dropna()
inplace=True in dieser Methode angeben.axis=1 setzt:
df_filme.dropna(axis=1)
axis=1 Parameter auf sich? Es ist nicht sofort ersichtlich, woher der Parameter "axis" kommt und warum der Wert gleich 1 sein muss, damit die Spalten beeinflusst werden. Um zu sehen warum, schau dir einfach die .shape Ausgabe an:
df_filme.shape
(250, 5)
axis=1die Spalten beeinflusst. Der Ursprung entstammt von NumPy. Und zeigt einmal mehr, dass es sich lohnt NumPy zu lernen.Imputation
bewertungsAnzahl an. Zuerst speichern wir die Daten dieser Spalte in eine eigene Variable:
bewertungen = df_filme['bewertungsAnzahl']
Dictionaries als Spaltennamen verwendet wurden. Wenn wir nun die Spalten eines DataFrames auswählen, verwenden wir eckige Klammern, als ob wir auf ein Python-Dictionary zugreifen würden.
bewertungen.head()

Titel-Index.
bewertungsAnzahlMittelwert = bewertungen.mean()
bewertungsAnzahlMittelwert
621591.6081632653
.fillna():
bewertungen.fillna(bewertungsAnzahlMittelwert, inplace=True)
bewertungen durch den Mittelwert der Spalte ersetzt. Wichtig zu wissen ist, dass wir durch die Verwendung von inplace=Truedas Original beeinflusst haben.
df_filme.isnull().sum()

Verstehen deiner Variablen
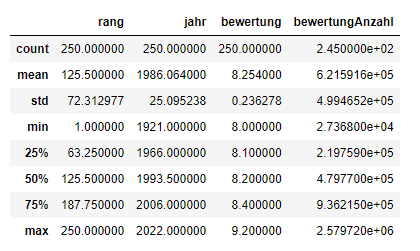
.describe()
describe()auf einem ganzen DataFrame können wir eine Zusammenfassung der Verteilung der kontinuierlichen Variablen erhalten:
df_filme.describe()
.describe()kann auch auf eine kategoriale Variable angewendet werden, um die Anzahl der Zeilen, die eindeutige Anzahl der Kategorien, die Top-Kategorie und die Häufigkeit der Top-Kategorie zu ermitteln:
df_filme['jahr'].describe()

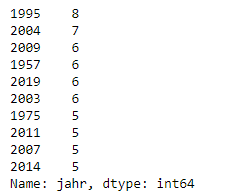
.value_counts()
.value_counts()kann uns die Häufigkeit aller Werte in einer Spalte anzeigen:
df_filme['jahr'].value_counts().head(10)
Beziehungen zwischen kontinuierlichen Variablen
.corr() können wir die Beziehung zwischen einzelnen kontinuierlichen Variablen erstellen:
df_filme.corr()
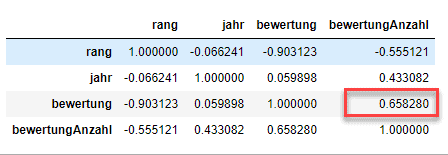
Rang eine perfekte Korrelation mit sich selbst hat, was offensichtlich ist. Auf der anderen Seite ist die Korrelation zwischen bewertung und bewertungsAnzahlmit +0,65 ein wenig interessanter.DataFrame slicen, selektieren & extrahieren
fillna() gespeichert.Nach Spalten
jahr_spalte = df_filme['jahr']
type(jahr_spalte)
pandas.core.series.Series
jahr_spalte = df_filme[['jahr']]
type(jahr_spalte)
pandas.core.frame.DataFrame
subset = df_filme[['jahr', 'bewertung']]
subset.head()
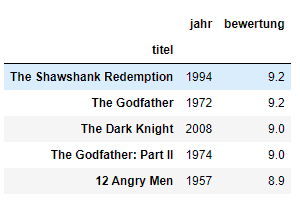
Nach Zeilen
.loc - lokalisiert nach Name.iloc- sucht nach numerischem Index.loc den Titel eines Films (z.B. The Dark Knight):
batman = df_filme.loc["The Dark Knight"]
batman

ilocden numerischen Index des Films an (bspw. hat The Dark Knight den Index 2):
batman = df_filme.iloc[2]
batman

loc und iloc kann man sich ähnlich wie List-Slicing in Python vorstellen.meinBeispiel[2:5].
subset_filme = df_filme.loc['The Dark Knight':'12 Angry Men']
subset_filme = df_filme.iloc[1:5]
subset_filme

.loc und .iloc, um mehrere Zeilen auszuwählen, ist, dass .locden Film 12 Angry Men in das Ergebnis einschließt..iloc verwenden, erhalten wir die Zeilen 2:5, aber der Film bei Index 5 (Schindlers Liste) ist nicht enthalten..ilocfolgt den gleichen Regeln wie das Slicen mit Listen. Das bedeutet, dass das Objekt am Index am Ende nicht enthalten ist.Auswahl mit Bedingung
bedingung = (df_filme['jahr'] == 2008)
bedingung.head()

isnull(), gibt dies eine Reihe von True und False Werten zurück.
bedingung = df_filme[df_filme['jahr'] == 2008]
bedingung
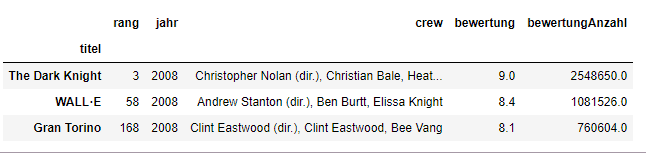
df_filme bei denen df_filme jahr gleich 2008 ist.
bedingung = df_filme[df_filme['bewertung'] >= 7.5].head(5)
bedingung

|&
bedingung = df_filme[(df_filme['jahr'] == 1997) & (df_filme['bewertung'] > 8.1)].head()
bedingung

isin()-Methode können wir das Ganze aber noch prägnanter machen:
bedingung = df_filme[df_filme['jahr'].isin([1997, 1998])].head()
bedingung

Anwenden von Funktionen
def filmKritiker(bew):
if bew >= 8.0:
return "gut"
else:
return "schlecht"
apply():
df_filme["bewertung_kritik"] = df_filme["bewertung"].apply(filmKritiker)
df_filme.head(2)

.apply() übergibt jeden Wert in der Bewertungsspalte durch die filmKritiker-Funktion und gibt dann eine neue Serie zurück.bewertung_kritik zugewiesen.bewertung_kritik:
df_filme["bewertung_kritik"] = df_filme["bewertung"].apply(lambda x: 'gut' if bew >= 8.0 else 'schlecht')
df_filme.head(2)

apply()viel schneller sein als eine manuelle Iteration über alle Zeilen. Der Grund dafür ist, dass Pandas eine Vektorisierung nutzt.apply()-Funktion häufig zur Anwendung kommt, ist bei natürlicher Sprachverarbeitung (NLP). Du wirst alle Arten von Textbereinigungsfunktionen auf Strings anwenden müssen, um sie für Machine-Learning-Zwecke vorzubereiten.Plotting - Ein Mini-Tutorial zur Datenvisualisierung
pip install matplotlib
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 21, 'figure.figsize': (10, 8)}) # setze Schriftart und vergrößert die Plotgröße
Einfache Tipps für Datenvisualisierung
Scatter-Plot
.plot() auf unser DataFrame df_filme anzuwenden. Weiterhin ist es hilfreich, einige Informationen zum Diagramm bereitzustellen (z.B. Name der X- und Y-Achse).
df_filme.plot(kind='scatter', x='jahr', y='bewertung', title='Jahr vs. Bewertung');
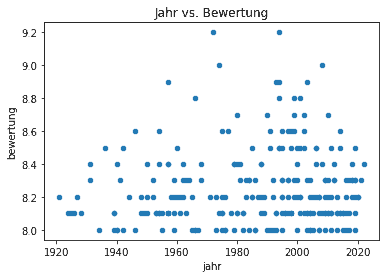
Histogramm
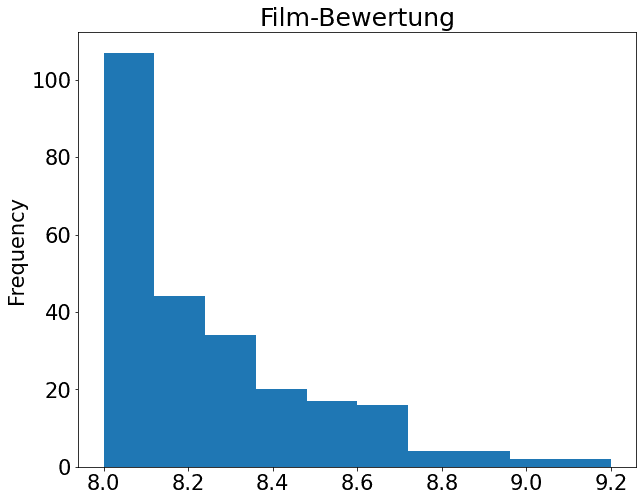
df_filme['bewertung'].plot(kind='hist', title='Film-Bewertung');
Box-Plot
.describe() am Anfang dieses Tutorials?describe()für die Bewertungsspalte liefert:
df_filme['bewertung'].describe()
df_filme['bewertung'].plot(kind="box")

Zusammenfassung zum Pandas Tutorial




